[Excel偵偍偗傞夞婣暘愅 乮5乯愢柧曄悢偵娭偡傞弌椡] 
Excel乮僄僋僙儖乯偵偍偗傞夞婣暘愅偺庤弴偲弌椡偺堄枴傪愢柧偟傑偡丅
偙偺儁乕僕偱偼丄愢柧曄悢偵娭偡傞弌椡傪愢柧偟傑偡丅
Excel偵偍偗傞夞婣暘愅乮嵟彫擇忔朄乯梡棎悢僨乕僞丗棎悢傪梡偄偰丄悇掕抣偺嫇摦傪尒傞偙偲偺偱偒傞Excel乮栺100KB乯偱偡丅
暘嶶偺晄曃悇掕検丗曃嵎暯曽榓傪乮n-1乯偱妱傞偲暘嶶偺晄曃悇掕検偵側傞偙偲偑帇妎揑偵妋擣偱偒傞Excel乮栺80KB乯偱偡丅
拞怱嬌尷掕棟偲媅帡惓婯棎悢丗堦條暘晍偺昗杮暯嬒偑惓婯暘晍偵嬤偯偔偙偲傗摑寁偵偍偗傞専掕偺傾僀僨傿傾偑帇妎揑偵妋擣偱偒傞Excel乮栺60KB乯偱偡丅
妛峑偼恖揑帒杮傪宍惉偡傞偺偐? (1)嫵堢偺宱嵪妛丗暘晍傗僔儈儏儗乕僔儑儞傪巊偭偰丄妛楌偲暯嬒捓嬥偺娭學傪愢柧偡傞HTML偱偡丅
妛峑偼恖揑帒杮傪宍惉偡傞偺偐? (2)捓嬥奿嵎偺幚徹暘愅丗擔杮偺妛楌娫捓嬥奿嵎偺幚徹暘愅傪愢柧偡傞HTML偱偡丅
栚師 丗 乮4乯夞婣暘愅慡懱偵娭偡傞弌椡偐傜偺懕偒偱偡丅
偙偺儁乕僕偱偼丄埲壓偺傛偆偵昞帵偝傟傞愢柧曄悢偵娭偡傞弌椡傪愢柧偟傑偡丅

5.1丂乲悇掕乴學悢丗愢柧曄悢1扨埵偺憹壛佀旐愢柧曄悢傊偺岠壥
乲悇掕乴學悢偼丄愢柧曄悢偺1扨埵偺憹壛佀旐愢柧曄悢傊偺岠壥偺悇掕抣傪帵偟偰偄傑偡丅 夞婣暘愅偺悇掕學悢偼丄3.3丂悇掕學悢偼暯嬒揑側岠壥偵側傞偵帵偟偨傛偆偵暯嬒揑側岠壥偵懳墳偟偰偄傑偡丅傑偨丄愗曅偼懠偺愢柧曄悢偑慡偰0偺帪偺旐愢柧曄悢偺摉偰偼傔抣傪帵偟偰偄傑偡丅
- 愢柧曄悢偺扨埵傪曄偊乮枩墌傪墌偵偡傞摍乯10000攞偵偟偨応崌丄悇掕學悢偼
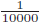 攞偝傟丄挷惍偝傟傑偡丅
攞偝傟丄挷惍偝傟傑偡丅
5.2丂乲悇掕學悢偺乴昗弨岆嵎丗悇掕學悢偺晄妋偐偝
悇掕學悢偼丄偁偔傑偱悇掕偟偰偄傞傢偗偱偡偐傜丄恀偺學悢偐傜偺槰棧偑梊憐偝傟傑偡丅偙偺槰棧偺巜昗偑悇掕學悢偺昗弨岆嵎偱偡丅乲悇掕學悢偺乴昗弨岆嵎偼丄悇掕學悢偺晄妋偐偝傪帵偟偰偄傑偡丅 悇掕學悢偺昗弨岆嵎偑彫偝偄偲丄悇掕惛搙偑崅偄偙偲偵側傝傑偡丅昗弨岆嵎偼丄埲壓偺傛偆側梫場偵傛偭偰曄壔偟傑偡丅
[2] 愢柧曄悢偺偽傜偮偒偑戝偒偔丄傛偔摦偄偰偔傟偨曽偑悇掕學悢傪應傝傗偡偔丄悇掕學悢偺昗弨岆嵎偼彫偝偔側傝傑偡丅
[3] 僄儔乕偺偽傜偮偒偑戝偒偄偲悇掕學悢傪應傝偯傜偔丄悇掕學悢偺昗弨岆嵎偼戝偒偔側傝傑偡丅
[4] 愢柧曄悢摨巑偑憡娭傪帩偮応崌偼丄偳偺愢柧曄悢偺岠壥偐傪敾暿偟偯傜偔丄悇掕學悢偺昗弨岆嵎偼戝偒偔側傝傑偡丅
[2]乣[4]偵娭偟偰丄棎悢僨乕僞偺[棎悢僔乕僩]偺愝掕傪曄偊偰F9傪墴偡偙偲偱妋擣偱偒傑偡丅[2]偵娭偟偰偼丄乹F4, F5乺偺抣傪戝偒偔偡傞偲愢柧曄悢偺偽傜偮偒傪戝偒偔側傝丄悇掕學悢偺昗弨岆嵎偑尭彮偡傞偙偲偑暘偐傝傑偡丅[3]偵娭偟偰偼丄乹B7乺偺抣傪戝偒偔偡傞偲僄儔乕偺偽傜偮偒偑戝偒偔側傝丄悇掕學悢偺昗弨岆嵎偑憹壛偡傞偙偲偑暘偐傝傑偡丅[4]偵娭偟偰偼丄乹B6乺偺戝偒偝傪[-1乣1]偺娫偱曄峏偟偰丄愢柧曄悢摨巑偺憡娭傪愝掕偱偒傑偡丅愢柧曄悢偺![]() 偲
偲![]() 偑撈棫偲側傞0傪擖椡偡傞偲丄偳偪傜偺愢柧曄悢偺岠壥偐偑敾暿偟傗偡偔丄昗弨岆嵎偑彫偝偔側傞偙偲偑暘偐傝傑偡丅堦曽偱亇1偵嬤偄抣傪擖椡偡傞偲丄悇掕學悢偺昗弨岆嵎偼戝偒偔側傞偙偲偑暘偐傝傑偡丅
偑撈棫偲側傞0傪擖椡偡傞偲丄偳偪傜偺愢柧曄悢偺岠壥偐偑敾暿偟傗偡偔丄昗弨岆嵎偑彫偝偔側傞偙偲偑暘偐傝傑偡丅堦曽偱亇1偵嬤偄抣傪擖椡偡傞偲丄悇掕學悢偺昗弨岆嵎偼戝偒偔側傞偙偲偑暘偐傝傑偡丅
- 愢柧曄悢偺扨埵傪曄偊乮枩墌傪墌偵偡傞摍乯10000攞偵偟偨応崌丄昗弨岆嵎偼攞偝傟丄挷惍偝傟傑偡丅
- 愢柧曄悢偺憡娭學悢偑亇1偱丄姰慡側懡廳嫟慄惈偑偁傞応崌偼偳偪傜偺愢柧曄悢偺岠壥偐傪敾暿偱偒傑偣傫丅Excel偺夞婣暘愅偱偼丄帺摦偱姰慡側嫟慄娭學偵偁傞愢柧曄悢傪徣偒丄徣偄偨愢柧曄悢偺昗弨岆嵎偼0偵側傝傑偡丅側偍丄Excel偑帺摦偱愢柧曄悢傪徣偄偨応崌丄乹暘嶶暘愅昞乺偺寢壥偼晄惓妋偵側傝傑偡丅
5.3丂t乲抣乴丗婎弨惛搙偱昡壙偟偨悇掕學悢
悇掕學悢偺昗弨岆嵎偼丄悇掕惛搙偲昞棤堦懱偱偡丅傛偭偰丄昗弨岆嵎偱挷惍偡傟偽丄婎弨偺悇掕惛搙偱悇掕學悢傪昡壙偱偒傑偡丅埲壓偺(22)幃偺傛偆偵丄t抣偼昗弨岆嵎偱妱傞偙偲偱婎弨惛搙偱昡壙偟偨悇掕學悢偱偡丅
| (22) |
悇掕學悢偺愨懳抣偑戝偒偗傟偽丄t抣偺愨懳抣傕戝偒偔側傝傑偡丅傑偨丄悇掕學悢偺昗弨岆嵎偑彫偝偗傟偽(22)幃偺暘曣偑彫偝偔側傝丄t抣偑戝偒偔側傝傑偡丅
- 愢柧曄悢偺扨埵傪曄偊乮枩墌傪墌偵偡傞摍乯10000攞偵偟偨応崌丄暘巕偺悇掕學悢傕暘曣偺昗弨岆嵎傕攞偝傟丄t抣偼曄傢傝傑偣傫丅
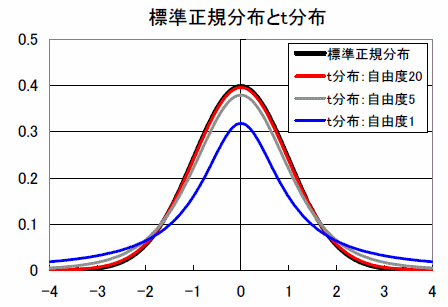
t抣傪梡偄偰亀愢柧曄悢偺恀偺岠壥偑0偱偁傞亁偲偄偆婣柍壖愢傪専掕偡傞偙偲偑偱偒傑偡丅婣柍壖愢偑惓偟偗傟偽丄t抣偼t暘晍偵廬偆偙偲偑抦傜傟偰偄傑偡丅t暘晍偼丄壓恾偺傛偆偵0傪拞怱偵嵍塃懳徧偵偽傜偮偔嶳宍偺暘晍偱偡丅t暘晍偼帺桼搙偑忋偑傞偲昗弨惓婯暘晍偵嬤偯偒傑偡丅帺桼搙偑20埲忋側傜丄幚柋忋偼昗弨惓婯暘晍偲峫偊偰嵎偟巟偊偁傝傑偣傫丅t暘晍傗昗弨惓婯暘晍偵偍偄偰丄愨懳抣2偐傜偼傒弌偡柺愊偺妱崌偼丄僾儔僗懁偲儅僀僫僗懁偺偦傟偧傟栺2.5%偱椉懁栺5%偱偡丅婣柍壖愢偺傕偲 偱偼栺95%偺妋棪偱丄t抣偼愨懳抣2埲壓偵廂傑傝傑偡丅
- 拞怱嬌尷掕棟偲媅帡惓婯棎悢偱F9傪墴偣偽丄昗弨惓婯暘晍偵偍偄偰栺95%偑亇2偺斖埻偵擖傞偙偲偑帇妎揑偵妋擣偱偒傑偡丅
t抣偑愨懳抣2埲壓偵廂傑傟偽丄亀慜採偲偟偰偄偨婣柍壖愢偺傕偲丄栺95%偺妋棪偺斖埻偱敪惗偡傞偁傝傆傟偨t抣偩偭偨亁偲偄偆夝庍偵側傝傑偡丅 堦曽偱丄t抣偑愨懳抣偱2傪挻偊偨帪偺夝庍偼丄擇捠傝偁傝傑偡丅堦偮偺夝庍偼亀婣柍壖愢偺傕偲偱丄5%埲壓偱偟偐敪惗偟側偄捒偟偄t抣偩偭偨亁偱偡丅傕偆堦偮偺夝庍偼亀5%埲壓偱偟偐敪惗偟側偄t抣偑弌傞偺偼晄帺慠偩丅慜採偲偟偨乽愢柧曄悢偺恀偺岠壥偑0偱偁傞乿偲偄偆婣柍壖愢偑娫堘偭偰偄偨丅亁偱偡丅偳偪傜偺夝庍傪偡傋偒偐偼暘愅幰傗撉幰偺敾抐偵傕埶懚偟傑偡丅偨偩t抣偑栺1.7偱偁傟偽亀10%偱敪惗偡傞捒偟偄t抣偩偭偨亁偲尵偭偰傕嬯偟偔偁傝傑偣傫偑丄t抣偑栺2.5偱偁傟偽亀1%偱敪惗偡傞捒偟偄t抣偩偭偨亁偲尵偆偺偼嬯偟偔側傝傑偡丅 t抣偺愨懳抣偑戝偒偄傎偳亀捒偟偄偙偲亁偲偄偆夝庍傛傝亀晄帺慠側偙偲佀慜採偲偟偨婣柍壖愢偑娫堘偭偰偄偨丅亁偲偄偆夝庍偺曽偑傕偭偲傕傜偟偔側傝傑偡丅
- 亀偁傝傆傟偨t抣亁偲夝庍偡傞斖埻偵擖偭偰傕丄愢柧曄悢偺恀偺岠壥偑0偱側偄働乕僗偼廫暘峫偊傜傟傑偡丅偙偺斖埻偵擖偭偰傕亀婣柍壖愢傪斲掕偟偵偔偄亁偲尵偊傞偩偗偱亀婣柍壖愢偑惓偟偄亁偲偼尵偊傑偣傫丅
- 戙昞揑側桳堄悈弨傗帺桼搙偵偍偗傞t抣偼丄摑寁偺嫵壢彂偺姫枛側偳偵偁傞t暘晍昞偱徠崌偱偒傑偡丅傑偨Excel娭悢偱[=TINV(妋棪, 帺桼搙)]傪巊偆偙偲傕偱偒傑偡丅椉懁5%丄帺桼搙47偱偼[=TINV(0.05, 47)]偲擖椡偡傞偲丄2.012偲弌椡偝傟傑偡丅
僉儕偺椙偝傗姷椺偐傜丄敾掕婎弨傪椉懁偱5%乮曅懁偱2.5%乯偲偡傞偙偲偑堦斒揑偱偡丅 偙偺応崌丄慜弎偟偨傛偆偵t抣偑愨懳抣偱2傪挻偊偰偄傞偐傪栚埨偵偱偒傑偡丅t抣偑愨懳抣偱2傪愗偭偰偄傟偽亀婣柍壖愢偺慜採偺傕偲丄栺95%偺妋棪偺斖埻偱敪惗偡傞偁傝傆傟偨t抣佀岠壥偺側偄愢柧曄悢偐傕偟傟側偄丅亁偲偄偆夝庍偵側傝傑偡丅堦曽偱丄t抣偑愨懳抣偱2傪挻偊偰偄傟偽亀婣柍壖愢偺慜採偺傕偲偱偼丄5%埲壓偱偟偐敪惗偟側偄t抣佀岠壥偺偁傞愢柧曄悢偲峫偊傞偺偑帺慠偱偁傞丅亁偲側傝傑偡丅
- 亀椉懁5%偺桳堄悈弨亁偲偄偭偨宍偱丄桳堄悈弨(significance level)偲偄偆梡岅傕巊傢傟傑偡丅
傑偨丄t抣傪梡偄偨専掕偼亀悇掕惛搙傪傆傑偊偰丄岠壥偑0側偺偐丠亁傪敾掕偟偰偄傑偡丅偙偺偨傔亀悇掕學悢偺愨懳抣偑彫偝偔偲傕丄悇掕惛搙偑崅偄曄悢亁傪岠壥偺偁傞愢柧曄悢偲敾掕偟傑偡丅 堦曽偱亀悇掕學悢偺愨懳抣偑戝偒偔偲傕丄悇掕惛搙偑掅偄曄悢亁傪岠壥偺側偄愢柧曄悢偐傕偟傟側偄偲敾掕偟傑偡丅t抣偼丄椙偔傕埆偔傕晄妋偐偝傪峫椂偟偰偄傞偺偱悇掕學悢偲巊偄暘偗傞昁梫偑偁傝傑偡丅
- 枩扨埵偺昗杮偑偁傞僨乕僞偱偼丄5.2丂乲悇掕學悢偺乴昗弨岆嵎偺[1]偐傜悇掕學悢偺昗弨岆嵎偑嬌抂偵彫偝偔側傝傑偡丅偙偺応崌丄0偵嬤偄悇掕學悢偱偁偭偰傕丄t抣偼嬌傔偰戝偒偔側傝傑偡丅
5.4丂P抣丗t抣偺専掕偺嫬栚偲側傞妋棪
帺桼搙偑掅偄応崌傗椉懁5%埲奜偺敾掕婎弨傪梡偄傞応崌側偳丄愨懳抣2傪栚埨偵偡傞t抣偺敾掕偑偱偒側偄応崌傕偁傝傑偡丅摑寁偺杮偵偁傞t暘晍昞傪尒傟偽丄奺帺桼搙偲t抣偱丄婣柍壖愢傪慜採偲偟偨応崌偵廂傑傞敾掕婎弨傪挷傋傞偙偲偑偱偒傑偡丅偟偐偟丄t暘晍昞偼巻柺偺搒崌偐傜丄嬫愗傝偺椙偄帺桼搙傗敾掕婎弨偟偐宖嵹偝傟偰偄傑偣傫丅傑偨丄専掕偺偨傃偵帺桼搙傪徠崌偟偰t暘晍昞傪尒傞偺偼柺搢偱偡丅偦偆偟偨柺搢側偙偲偼丄僐儞僺儏乕僞乕偵擟偣偰敾掕婎弨偺嫬栚傪弌椡偡傞偺偑P抣偱偡丅 P抣偼亀愢柧曄悢偺岠壥偑0偱偁傞亁偲偄偆婣柍壖愢偺傕偲偱丄暘愅寢壥偺t抣偑弌傞嫬栚偺妋棪傪帵偟偰偄傑偡丅
- p抣偲彫暥帤偱昞婰偝傟傞応崌傕偁傝傑偡丅傑偨丄P抣偵偼桳堄妋棪偲偄偆栿岅傕巊傢傟傑偡丅
椺偊偽丄帺桼搙偑100偱t抣偑2.123偺応崌丄椉懁5%偺敾掕婎弨偱偼亀婣柍壖愢偺傕偲偱捒偟偄丄傕偟偔偼晄帺慠側t抣亁偱偡偑丄椉懁1%偺敾掕婎弨偱偼亀婣柍壖愢偺傕偲偱傕丄偁傝傆傟偨t抣亁偵側傝傑偡丅偙偺5%偲1%偺娫偵嫬栚偑偁偭偨偼偢偱偡丅偙偙偱t抣偺塃椬偺僙儖偵P抣偑0.0362偲昞帵偝傟傞偙偲偐傜丄嫬栚偲側傞敾掕婎弨偑椉懁3.62%偱偁傞偙偲偑暘偐傝傑偡丅 傑偨丄椉懁5%偺敾掕婎弨偵娭偟偰傕丄亀t抣偑愨懳抣偱2傪挻偊偰偄傞偐丠亁偺栚埨傛傝傕亀P抣偑0.05傪愗偭偰偄傞偐丠亁偺曽偑丄帺桼搙傪峫椂偟偰偄偰惓妋偱偡丅
- Excel娭悢偱傕[=TDIST(t抣, 帺桼搙, 椉懁=2)]偲擖椡偡傟偽丄嫬栚偱偁傞P抣傪昞帵偟傑偡丅[=TDIST(2.123, 100, 2)]偱丄0.0362偑弌椡偝傟傑偡丅
5.5丂乲怣棅嬫娫偺乴壓尷, 忋尷丗恀偺岠壥偑偁傝偦偆側斖埻
悇掕學悢偵傛偭偰堦揰偱帵偝傟偰偄傞抣偑丄恀偺學悢偵堦抳偡傞偲峫偊傞偺偼妝娤揑偱偡偑丄恀偺學悢偼悇掕學悢偺嬤偔偵偁傞偲峫偊傞偺偑帺慠偱偡丅傑偨丄悇掕學悢偺昗弨岆嵎偑彫偝偔悇掕惛搙偑崅偗傟偽丄悇掕學悢偲恀偺學悢偼傛傝嬤偄偲峫偊傜傟傑偡丅乲怣棅嬫娫偺乴壓尷, 忋尷95%偼丄怣棅學悢95%偱恀偺學悢偑偁傝偦偆側斖埻傪帵偟偰偄傑偡丅
- 偙偙偱妋棪偲尵傢偢丄怣棅學悢偲偄偆尵梩傪梡偄傞偺偼丄恀偺學悢偼暘愅幰偵偼偭偒傝偲暘偐傜側偄偩偗偱丄屌桳偺抣偑偁傞偲偄偆敪憐偐傜棃偰偄傑偡丅椺偊偽丄偼偭偒傝偲暘偐傜側偔偰傕亀惣楋100擭偵戝抧恔偑婲偙偭偨偐丠亁偵懳偟偰亀妋棪仜%偱婲偙偭偨亁偲偼尵偄傑偣傫丅偟偐偟丄怣棅學悢偲偄偆尵梩偵撻愼傔側偗傟偽丄庡娤揑側妋棪偲撉傒偐偊偰傕偐傑偄傑偣傫丅
- 夞婣暘愅偺僟僀傾儘僌儃僢僋僗偱95%埲奜偺怣棅學悢傪慖戰偡傞偙偲傕偱偒傑偡丅傑偨丄棎悢僨乕僞偺[棎悢僔乕僩]偱偼丄乹R23乺偱巜掕偱偒傑偡丅
栚師 丗 乮6乯幚徹暘愅傪峴偆嵺偺拲堄揰偵懕偒傑偡丅